
「Oracleデータベースのキャラクタセットは JA16SJISTILDE で」なんておっしゃる方は、いまだに漢字は2byte、英数字は1byte という悪しき感覚を持っておられる方々です。私(50歳前後)らの世代のSEは、いまだにこういう感覚のまま設計をされる方が多数おられます。
Windows XP までは、まだこういう考え方でも通用してましたが、Windows 7 以降をクライアントとした場合、このキャラクタセットの場合、トラブルが多発することになります。何が問題なのか?それは一部文字が格納できずに化けてしまうのです。「森鷗外」と作家をご存じでしょうか?実は「鷗」の字を JA16SJISTILDE のデータベースに格納すると文字化けしてしまいます。下のハードコピーは DATA NVARCHAR2(6), DATA2 VARCHAR2(6) の2つのカラムを持つテーブルに「鷗外」というデータを登録した場合のSELECT結果です。

見事に文字化けしています。しかし、AL32UTF8 のデータベースで同じことを行うと、
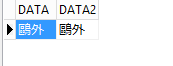
と問題なく登録できていることがわかります。この文字は XP にはなかった文字なのですが、Windows 7 から扱うことが可能になりました。ですので Windows 7 以降のクライアントを持つシステムを構築する時に、Oracle データベースで JA16SJISTILDE を採用する際は、登録不可能な文字チェックを行い除外してやらないと文字化けしてしまうことになります。特に理由のない限りキャラクタセット AL32UTF8 を採用すべきです。
次に漢字2byte、英数字1byte の設計をしてしまう古いSEの問題。我々MS-DOS時代から Shift JIS に慣れ親しんだ技術者は漢字が2byte、英数字(正確には記号も入るからANK文字と言うべきか)は1byteという前提でシステムを作ってきました。そして、そういう人達が作ったシステムを使ってきた方々もなんとなく漢字は英数字の倍の領域をとると思っています。全角、半角という言い方が象徴していますね。漢字は全角で英数字は半角なのです。だから昔のソフトの説明書には「この入力域は12byte長の文字を入力できます」と書かれていたのです。この場合だと全角文字ばかりなら6文字、半角文字ならば12文字が入力できる。混在する場合は全角2byte、半角1byteで計算して、、、と考えたのです。
しかし時代は変わりました。今は全角漢字であろうが半角英数字であろうが1文字だと考え文字数で計算します。今のソフトの説明書には「この入力域は6文字入力できます」と書かれています。これは「全角であろうが半角であろうが6文字しか入力できません」ということです。たとえ混在してても入力できるのは文字数で6文字です。Oracle データベースもこれに対応した型が導入されています。先頭にNがつく型、NVARCHAR2 や NCHAR です。この型で定義する長さは文字数となります。一方、昔ながらの VARCHAR2 は定義する長さが byte 数指定です。すると文字を格納する時に厄介なことになります。実は、UNICODE(UTF-8)の英数字は1byte、漢字は概ね3byte、時々4byte なのです。現場の技術者でも、よく漢字は3byte と誤解している方がいらっしゃいます。しかしそうではありません。サロゲートが必要な一部文字は4byteとなってしまいます。例えば VARCHAR2(12)に格納できる文字数は、サロゲート文字ばかりの場合は 12÷4 = 3 つです。普通の漢字だと 12 ÷ 3 = 4つです。英数字なら 12 ÷ 1 = 12 です。入力文字数でN文字の制限をかけたとすると、この文字を格納するために必要な VARCHAR2 は全てがサロゲート文字の場合を考慮して 4 × N byte の領域が必要です。しかし、先頭にNがつく型なら NVARCHAR2(N), NCHAR(N) で事足りるわけです。仕様としても見通しが良いですし無駄がないと思いませんか?
若い世代の方々は、古い世代のSEが信奉している「全角」「半角」「Shift JIS」神話に毒されることなく正しい道を歩んでいってください。どうしても Shift JIS に拘る必要があるのなら、入力時に登録不可能な文字をチェックすることをお忘れなく。これを怠ってしまうとクレームが来ること間違いありません。経験者からの忠告です。
